FJcloud実践
データベースも冗長化して、システムの単一障害点を解消する

システム構築において、高可用性は最も重要なテーマのひとつでしょう。以前ご紹介したように、ロードバランサーを利用したサーバーの冗長化は、高可用性を実現する一般的なアプローチですが、実はそれだけでは不十分です。本記事では、FJcloud-Vのマネージドデータベースサービス「RDBを活用して、データベースの冗長化を実現する方法を解説します。
データベースも冗長化しよう
ロードバランサーを利用したサーバーの冗長化は、可用性の向上以外にもメリットがあります。例えばオートスケールを利用することで、増大する負荷に自動的に対応して機会損失を抑えたり、負荷が低い時にはサーバーを減らしてコスト最適化をすることも可能です。ですが、こうしたクラウドのメリットを享受するためには、オンプレミス時代とは異なる、クラウドならではのインフラ構成が必要となります。
クラウドでは、サーバーが動的に増減します。そして新しく追加されたサーバーは既存のデータにアクセスできなくてはなりませんし、削除されるサーバーにデータを保存させておくわけにもいきません。つまり、必然的にストレージやデータベースは、サーバーの外部に確保し、ネットワーク越しに共有することになります。
ここで問題となるのが、サーバーを冗長化していても、データベースが1台だけだった場合、そのデータベースが単一障害点(SPoF)となってしまうことです。システム全体の可用性を高めるためには、データベースも冗長化する必要があるのです。
マネージドサービスのすすめ
サーバーは冗長化できているのですから、そのサーバーにデータベースエンジンをインストールすることで、高い可用性を持つデータベースを自前で構築することも可能です。しかし、この方法にはクリアしなければならない課題が多く存在するため、基本的にはお勧めしません。
冗長化されたデータベースを構築するのには、非常に手間がかかります。例えば、障害に備えた予備のデータベースは、どうスタンバイさせるのがよいのでしょうか。いざという時に障害を正しく検知できるでしょうか。また障害時のフェイルオーバーは正しく機能するでしょうか。その後のリカバリはどうしたらよいでしょう。こうした問題のハンドリングは、そのまま運用担当者の負担となってしまいます。
大切なのは、データベースはサービスを支える道具でしかないという点です。データを安全に保存し、検索、追加、更新といった操作ができるのであれば、その中身をどのように構築するかは本質ではありません。そして本質ではない部分は、なるべく簡略化、省力化すべきです。
インフラを自由に構築できるだけでなく、クラウド事業者が提供している様々な「マネージドサービス」が利用できる点も、クラウドのメリットのひとつです。FJcloud-Vでは「[RDB](https://pfs.nifcloud.com/service/rdb.htm)」というマネージドデータベースサービスを提供しており、簡単にMySQL/PostgreSQLのデータベースを構築できるようになっています。RDBには以下のような特徴があります。
- 2台のデータベースを用いて、簡単にアクティブ・スタンバイの冗長化構成を構築できる。
- 障害時にはフェイルオーバーが自動的に行われ、待機系のサーバーが昇格して運用を継続できる。
- リードレプリカの追加が簡単に行えるため、読み出しの負荷分散もできる。
- ゾーンやリージョンをまたいだ外部レプリケーションも可能。
- ポイントインタイムリカバリに対応しているため、万が一の場合も、任意の時点のデータベースを復元することができる。
- 面倒なデータベースのバックアップ作業を自動化できる。
- マネージドサービスであるため、面倒なメンテナンスを事業者に任せられる。
データベースは運用難易度が高いだけでなく、ビジネスの継続性に直結するサービスであるため、運用における失敗が許されません。このようなサービスは特別な理由がない限り、積極的にマネージドサービスを利用することをお勧めします。
データベースの作成方法
RDBを用いてデータベースを作成する、具体的な手順を紹介します。なおDBサーバーの作成に関するドキュメントも合わせて参照してください。
- FJcloud-Vのコントロールパネルにログインし、メニューから「RDB」を選択します。
- RDBのダッシュボードが開いたら「RDBサーバーを作成する」ボタンをクリックします。
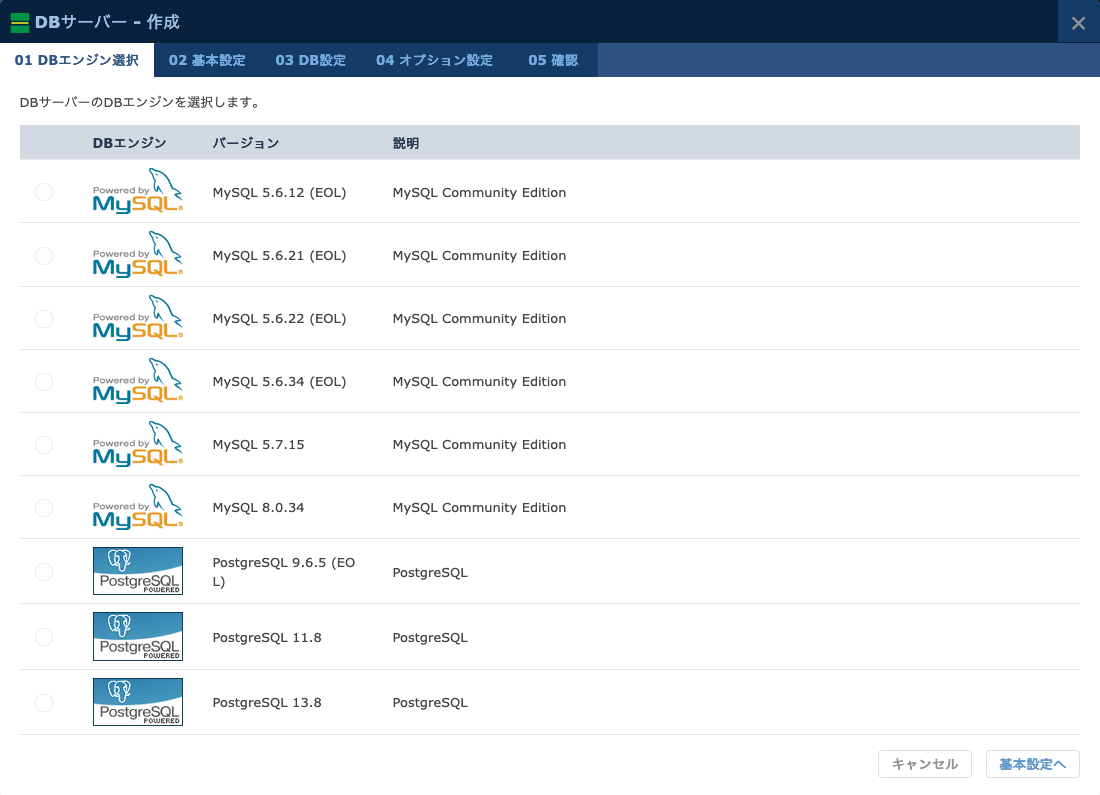
- DBエンジンを選択します。今回はMySQL 8.0.34を選択しました。
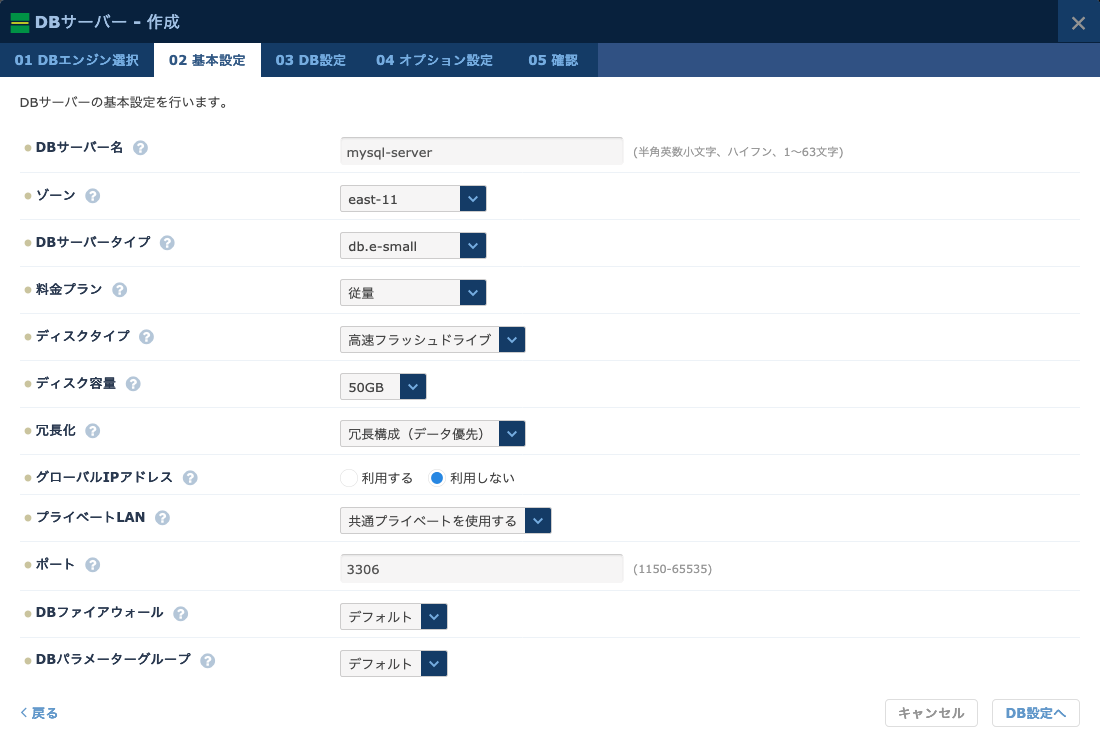
- DBサーバーの基本的な情報を入力します。
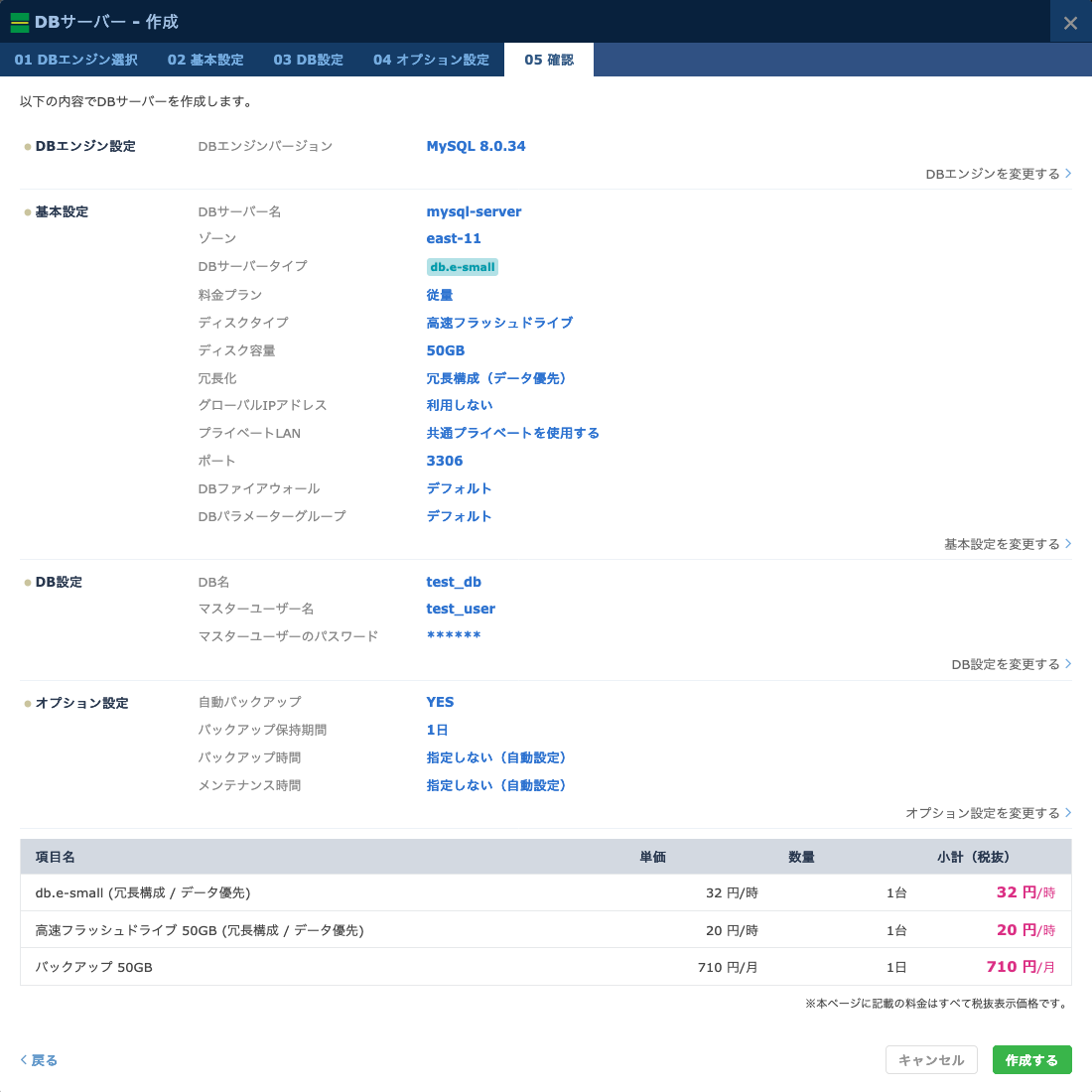
- DBサーバー名: DBサーバーのインスタンスにつける固有の名前です。わかりやすい名前をつけておきましょう。
- ゾーン: データベースサーバーを作成するゾーンです。
- DBサーバータイプ: DBサーバーのインスタンスタイプです。要求されるスペックに応じて選択しましょう。
- 料金プラン: 月額課金/従量課金が選択できます。
- ディスクタイプ: 標準フラッシュドライブ/高速フラッシュドライブが選択できます。
- ディスク容量: ディスクの容量を50GB〜250GBの範囲で、50GB刻みで選択できます。
- 冗長化: データベースを冗長化するか、シングル構成にするかが選択できます。この設定を「冗長構成」とすることで、主系のデータベースサーバーとは別の物理ホスト上に、自動で待機系のデータベースサーバーが作成されます。そして主系のデータベースサーバーが停止、または利用不能のなった場合は、自動でファイルオーバーが行われます。これにより待機系サーバーが主系に昇格し、運用を継続できます。
- グローバルIPアドレス: データベースにグローバルIPアドレスを付与するかを選択できます。データベースをグローバルに公開するのはリスクでしかないため、利用しない構成を推奨します。
- プライベートLAN: データベースサーバーが接続されるプライベートLANを選択します。データベースにアクセスするサーバーと同じLANを指定してください。
- ポート: データベースサーバーが待ち受けるポート番号を選択します。通常はデフォルトのままで問題ありません。
- DBファイアウォール: データベースサーバーのファイアウォールを選択します。ファイアウォールに許可設定を追加しないと、すべてのアクセスは遮断されるため、データベースに接続できません。こちらを参照して、サーバーからのアクセスを別途許可してください。
- DBパラメーターグループ: データベースサーバーに設定するパラメーターグループを選択します。パラメーターグループについて詳しくは、こちらを参照してください。
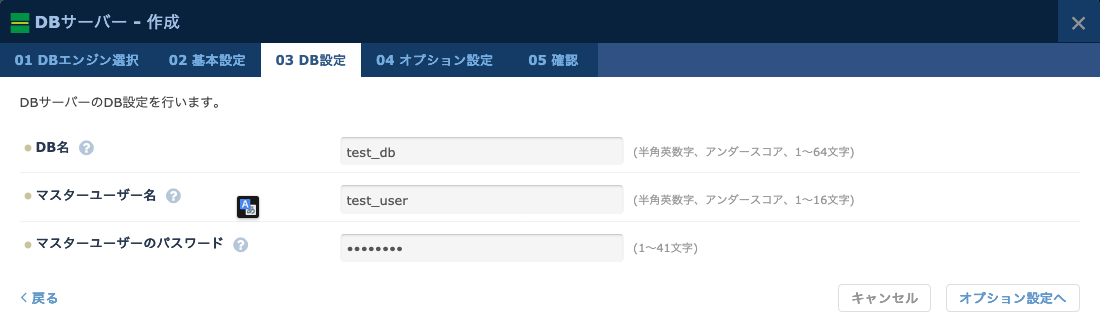
- データベースサーバー内に作成される、具体的なデータベースの設定を行います。データベース名、マスターユーザー名、パスワードを設定してください。
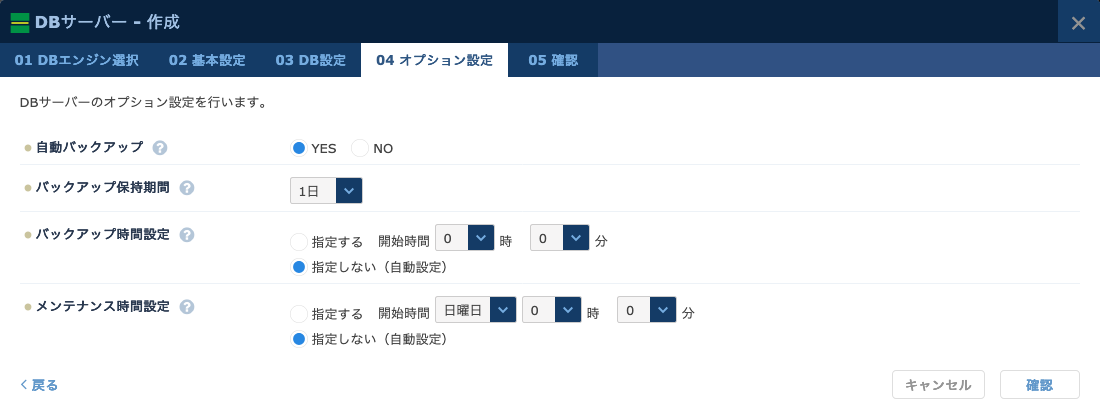
- データベースのバックアップに関する設定を行います。自動バックアップの有無、バックアップの保持期間、バックアップとメンテナンスの実行時間を設定できます。データベースの用途や運用ポリシーに応じて設定してください。
- 最後に設定した内容の確認が表示されます。問題なければ「作成する」をクリックしてください。
リードレプリカによる負荷分散
冗長化と同様に、複数のサーバーを用いたデータベースの構成に「リードレプリカ」があります。FJcloud-VのRDBは、リードレプリカにも対応しています。リードレプリカは、冗長化とはまったく異なる概念なのですが、複数のサーバーを用意して運用するという点が似ていることから、混同される方がいるかもしれません。そこでリードレプリカ機能についても、簡単に紹介します。
リードレプリカとは
リードレプリカとは、主系データベースサーバーの、読み取り専用のコピーの呼び名です。データベースに対するリクエストは、主にデータの検索といった読み取り処理と、データの追加、削除、更新といった書き込み処理に分けられます。リードレプリカは読み取り専用のサーバーのため、このうち読み取り処理のみを実行できるサーバーになります。例えばEC系のサイトなどでは、商品の検索クエリーが、データベースへのリクエストのほとんどを占めています。このように読み出し負荷のみが極端に高いシステムにおいては、読み出し処理を専用のサーバーに分散し、更新を行う主系サーバーと分離できるリードレプリカの効果は絶大です。RDBでは、MySQLやPostgreSQLに組込まれたレプリケーション機能を利用した、リードレプリカを作成できます。
なお主系データベースに対して行われた書き込みは、非同期でリードレプリカに反映されます。この「主系データベースに行われた書き込みがリードレプリカに反映されるまでの時間」を「レプリカラグ」と呼びます。レプリカラグが存在するため、わずかな遅延も許容できないようなシステムには向きません。またリードレプリカはあくまで負荷分散のためのシステムであり、高可用性を実現する冗長化とは異なる概念であることに注意してください。
FJcloud-Vにおけるリードレプリカの追加方法
RDBにリードレプリカを追加する手順を紹介します。詳しくはドキュメントも合わせて参照してください。
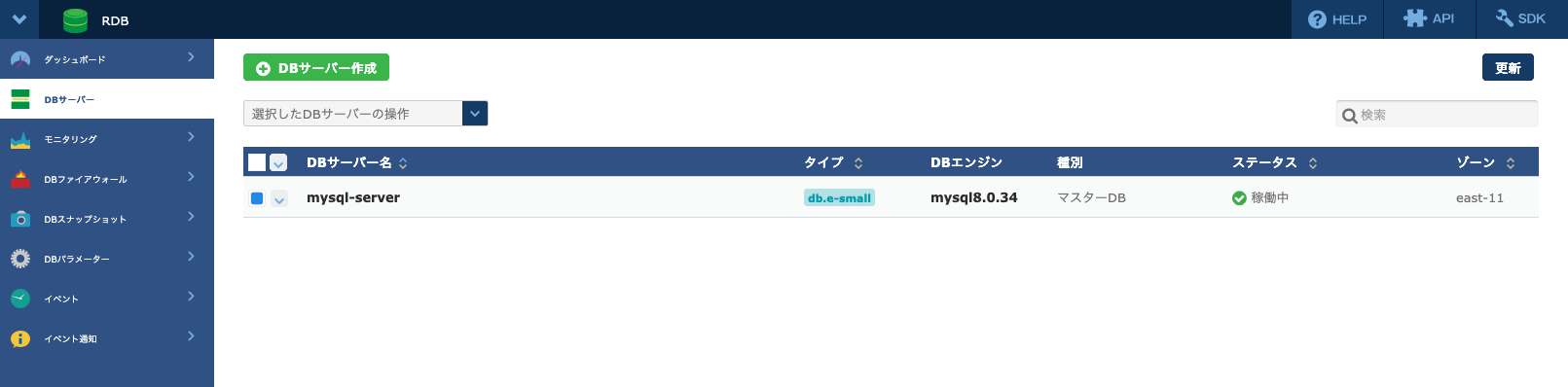
- RDBのダッシュボードを開き、前述の手順で作成されたデータベースサーバーを選択します。
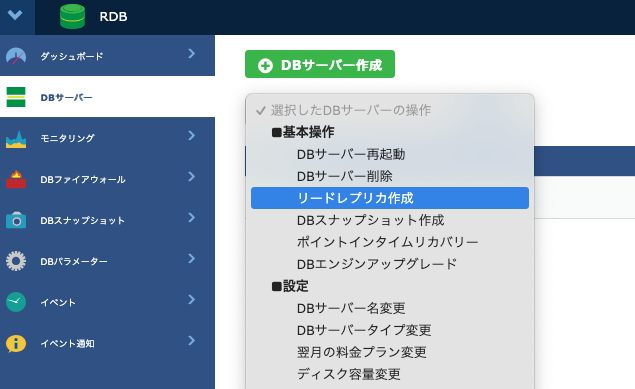
- 「選択したDBサーバーの操作」のプルダウンから、「リードレプリカ作成」を選択します。
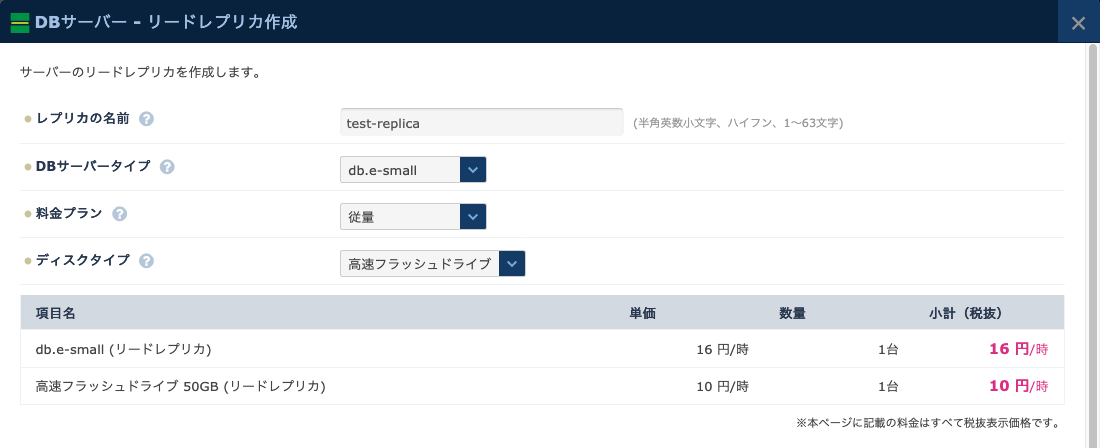
- リードレプリカに必要な情報を入力します。
- レプリカの名前: リードレプリカにつける固有の名前です。わかりやすい名前をつけておきましょう。
- DBサーバータイプ: リードレプリカのインスタンスタイプです。要求されるスペックに応じて選択しましょう。
- 料金プラン: 月額課金/従量課金が選択できます。
- ディスクタイプ: 標準フラッシュドライブ/高速フラッシュドライブが選択できます。
- 「作成する」ボタンをクリックします。
リードレプリカの作成が完了すると、アプリケーションからリードレプリカのプライベートIPアドレスに接続して、読み取りクエリを実行できます。読み取りクエリは積極的にリードレプリカに向けることで、主系データベースの負荷を軽減し、システム全体のパフォーマンスを向上させることができます。
まとめ
FJcloud-VのRDBサービスならば、データベースの冗長化を簡単に実現し、システムの単一障害点を解消することができます。また高い可用性だけでなく、メンテナンスやバックアップなどの手間から運用担当者を開放でき、リードレプリカを追加すれば、読み取りクエリの負荷分散も実現できます。
データベースはシステムの心臓部とも言える、重要なコンポーネントです。マネージドサービスを活用することで、運用の負担を軽減しながら高い可用性と信頼性を確保することができます。FJcloud-VのRDBサービスは、こうした要件を満たすための優れた選択肢となるでしょう。
